데이터 분석을 위한 기본 작업 중 하나가 데이터를 효율적으로 다루는 것이죠. 파이썬의 대표적인 데이터 분석 라이브러리인 Pandas를 활용하면, 데이터프레임 형태로 데이터를 조작하고 분석할 수 있습니다. 이번 글에서는 주피터 노트북(Jupyter Notebook)을 활용하여 Pandas를 이용한 데이터 불러오기 및 기본적인 확인 방법에 대해 다뤄보겠습니다.
1. 주피터 노트북 기본 사용법
- 주피터 노트북은 데이터 분석 및 프로그래밍을 편리하게 수행할 수 있는 환경을 제공합니다. 기본적인 단축키는 다음과 같습니다.
▲ Enter : 선택한 셀을 편집할 수 있도록 활성화
▲ Shift + Enter : 현재 셀 실행 및 다음 셀로 이동
▲ Esc : 명령 모드로 전환 (셀 선택 및 관리 기능)
▲ Esc 상태에서 M : '마크다운(Markdown)' 모드로 문서작성 가능
▲ A : 선택한 셀 위에 새로운 셀 추가
▲ B : 선택한 셀 아래에 새로운 셀 추가
▲ X : 선택한 셀 삭제
▲ Z : 삭제한 셀 복구
2. pandas 패키지 불러오기
- pandas는 데이터를 불러오고 조작하는 데 필수적인 라이브러리입니다. Pandas를 사용하기 위해서는 먼저 라이브러리를 불러와야 합니다. 일반적으로 다음과 같은 방식으로 pd라는 별칭(alias)을 사용하여 가져옵니다.
# pandas 패키지 불러오기
import pandas as pd3. 데이터 불러오기
- 서울시 열린 데이터광장에서 제공하는 데이터를 활용하여 데이터를 불러오는 방법을 살펴보겠습니다.
- 예제 데이터는 "서울시 지하철호선별 역별 승하차 인원 정보. csv" 파일입니다.
- 다음 코드를 실행하면 해당 데이터를 데이터 프레임으로 불러올 수 있습니다.
df = pd.read_csv("./s_data/서울시 지하철호선별 역별 승하차 인원 정보.csv", encoding='cp949')- pd.read_csv('파일경로')
- csv 파일을 읽어와 데이터프레임으로 변환
- 만일 csv 파일이 아닌 tsv 형식의 파일이라면, sep = "\t"를 추가해 주시면 됩니다. - "./s_data/서울시 지하철호선별 역별 승하차 인원 정보.csv"
- 파이썬 실행 공간에 s_data란 파일을 만들어 '서울시 지하철호선별 역별 승하차 인원 정보. csv'를 저장하였기에 파일 경로를 지정해 준 것입니다. - encoding='cp.949'
- 한글 데이터를 올바르게 불러오기 위해 사용하는 인코딩 옵션입니다.
- 에러명: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byte
- 위와 같은 에러명이 발생하였을 때 사용할 수 있는 코드입니다.
* encoding='UTF-8' : 또 다른 인코딩 방식으로 이 코드를 작성해야 하는 경우도 있습니다.
4. 데이터 확인하기
- 데이터를 불러온 후, 기본적인 확인 작업을 진행해야 합니다. 다음과 같은 주요 기능을 활용하여 데이터의 구조를 파악할 수 있습니다.
1) 처음 5개 행 보여주기
- 데이터프레임의 첫 5개 행을 출력하여 데이터가 어떻게 구성되어 있는지 확인할 수 있습니다.
df.head()
2) 마지막 5개 행 보여주기
- 데이터의 끝부분을 확인하고 싶다면, tail()을 사용하여 마지막 5개 행을 확인할 수 있습니다.
df.tail()
3) 데이터 타입 확인하기
- 해당 데이터가 Pandas의 데이터프레임인지 확인할 수 있습니다.
type(df)
4) 데이터 형태(행, 열) 확인하기
- shape를 사용하면 데이터프레임의 크기(행, 열 개수)를 확인할 수 있습니다.
- columns를 활용하면 데이터프레임이 포함하는 열의 이름을 확인할 수 있습니다.
# 행과 열 확인하기
df.shape
# 열 확인하기
df.columns
5) 각 열의 데이터 타입 확인하기
- 각 열이 숫자형인지, 문자형인지 등을 확인할 수 있습니다. 데이터 타입을 파악하면 이후 데이터 처리 및 변환이 용이해집니다.
df.dtypes
6) 데이터프레임의 주요 정보 확인하기
- info()를 사용하면 데이터프레임의 전체적인 개요를 확인할 수 있습니다. 이 함수는 데이터의 행 수, 열 수, 각 열의 데이터 타입 및 누락된 값의 개수(결측값) 등을 제공합니다.
df.info()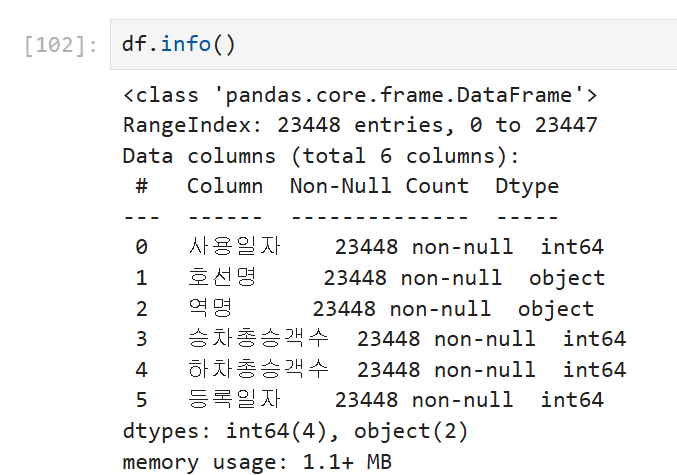
이번 글에서는 Pandas를 활용하여 데이터를 불러오고, 기본적인 확인 작업을 수행하는 방법을 살펴보았습니다. 데이터 분석을 진행하기 전, 이러한 기초 작업은 필수적으로 수행해야 합니다. 감사합니다:-)
'데이터 분석' 카테고리의 다른 글
| pandas (2) : 데이터 추출 방법 정리 / 주피터 노트북 (0) | 2025.02.10 |
|---|---|
| UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byte 해결방법 (0) | 2025.02.07 |
| 파이썬 내장 함수 (1) : 리스트와 관련된 내장 함수 - sum, max, min, sorted, map, abs, len (0) | 2025.02.07 |
| 파이썬 반복문 (2) : for문 - range(), 딕셔너리(dict) (0) | 2025.02.06 |
| 파이썬 반복문 (1) : while문 - break, continue, 무한루프 (0) | 2025.02.03 |